
Triliovault for Kubernetes is a cloud-based application-based data protection platform that was originally developed to meet the needs of scale, performance, and mobility from the Kubernetes container environment in a public or hybrid cloud environment. If you are looking for a storage company, you can search a company like kubevious that provides storage solutions.
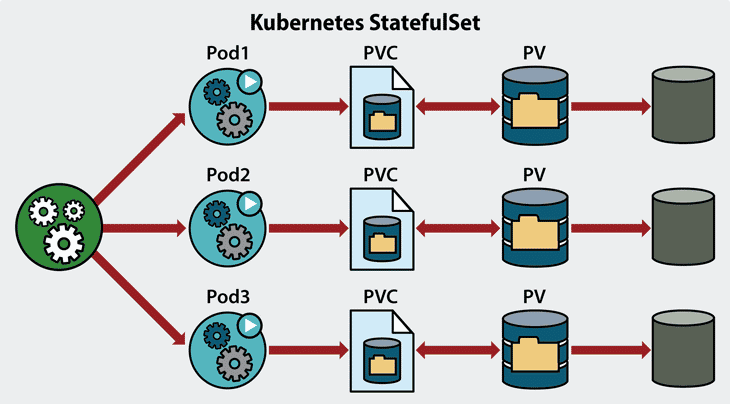
Image Source: Google
Triliovault for Kubernetes provides backup and recovery of all applications, including data, metadata, and other Kubernetes objects related to the application, so they are protected and can be restored at any time.
Why is Triliovault for Kubernetes?
TVK is more than your standard cloud backup and restores the platform. This is application-oriented and allows you to support and recover data, metadata, and all Kubernetes objects related to the application.
TVK also uses specific and detailed backup methods that allow you to back up using various names of helmets, labels, operators, and diagrams. TVK was born not only in the cloud but also in Kubernetes.
Therefore, TVK is packaged as an OpenShift operator and is implemented as a special definition of resources. In addition, TVK is compatible with cloud providers, from the private sector to public clouds, including AWS, GCP, and IBM, as well as various types of storage – CSI, NFS, S3.
There are three steps to use TVK on the OpenShift red cap or IBM Machine Cluster Kubernetes in the IBM cloud and in the IBM catalog.
Search Trail in the IBM catalog
Choose Target IBM Kubernetes or Red Hat OpenShift Service
Choose your clusters in IBM clouds – and use